


How to Plug Your Own External Machine Learning Models (BYOM) In Salesforce
Contributors: Paul Harmon, Keely Weisbeck
Back in the day, businesses needed lots of resources to build predictive models from scratch, including a data science team of qualified statistics experts to build and maintain models. Einstein Discovery from Salesforce allows companies to implement machine learning without needing a team of data scientists, integration experts, and architecture people to build and productionalize statistical models. Einstein Discovery empowers teams to quickly help find patterns in the data and take advantage of those patterns to make valuable predictions.
Einstein Discovery is Salesforce’s artificial intelligence and machine learning tool that allows users to easily gain insights into their data. Users can run data from Salesforce and various external systems through predictive models and use Discovery “Stories” to help investigate model results to surface insights that help businesses make informed decisions.
However, Einstein Discovery has its limitations. Discovery supports building custom models by choosing input variables, but it does not give users control over the algorithm and its tuning parameters. External programs like R or Python are also not supported. Discovery expects data to be resident in CRM Analytics(CRMA) to build models, posing limitations with building models on data residing outside CRMA or Salesforce.
CRMA External Models, or BYOM (Bring Your Own Model), allows businesses to extend Einstein Discovery functionality by gaining access to more custom Python machine learning models. It allows users to bring their own TensorFlow-based Python models and platform them in Einstein Discovery. With External Models, powerful models can be built using data on any enterprise data platforms, not limiting Discovery to being a CRM data science tool. This makes the CRMA platform very powerful, and it can be used as an enterprise data science platform to publish machine learning models beyond just the out-of-the-box Discovery algorithm.
Einstein Discovery models work well, but data scientists hesitate to use black-box models when making high-stake decisions. Now, with External Model, the Discovery platform is even more powerful and flexible. Users can build quick Discovery models to solve common problems and have data scientists build custom deep learning models to solve complex ones.
Once the model is ready, it only takes a few clicks to publish. The speed to production models along with its monitoring and governance framework make Discovery a serious tool to consider for modern data science teams.
Comparison between tools: how does External Model/BYOM measure up
The table below shows a comparison between Einstein Discovery, BYOM, and custom models built in Azure/AWS/on-prem servers etc. While custom modeling tools can provide significant flexibility, they also add complexity in developing and maintaining models. ED out of the box provides speed-to-value in building models, but extending to BYOM can give a user more flexibility in choosing custom algorithms.
| ED | BYOM | CUSTOM | |
| Framework | Black box algorithm | Tensorflow | Tensorflow, PyTorch, Scikit-learn, etc. |
| Citizen Data Science | Very friendly | Middle – requires some code | Requires substantial code |
| Speed to Implement | Lightning-fast | Middle | Slow |
| Python | Not available | Specific libraries supported | Very flexible |
| Solve Complex Problems | Moderately powerful | Powerful with deep learning models | Mighty powerful |
| Flexibility | Limited options | More flexible – options for custom optimizers and loss functions | Very flexible |
| Shap Values for Model Interpretation | Yes | No | No – would need to custom build |
Using The Tool:
Let’s look at how to get the BYOM model up and running on the CRMA platform.
Here are the steps involved:
1. Set up Docker container
The first step is to set up the development environment for machine-learning models. We should be using only the libraries and versions supported by this platform. Below is the list of supported libraries.
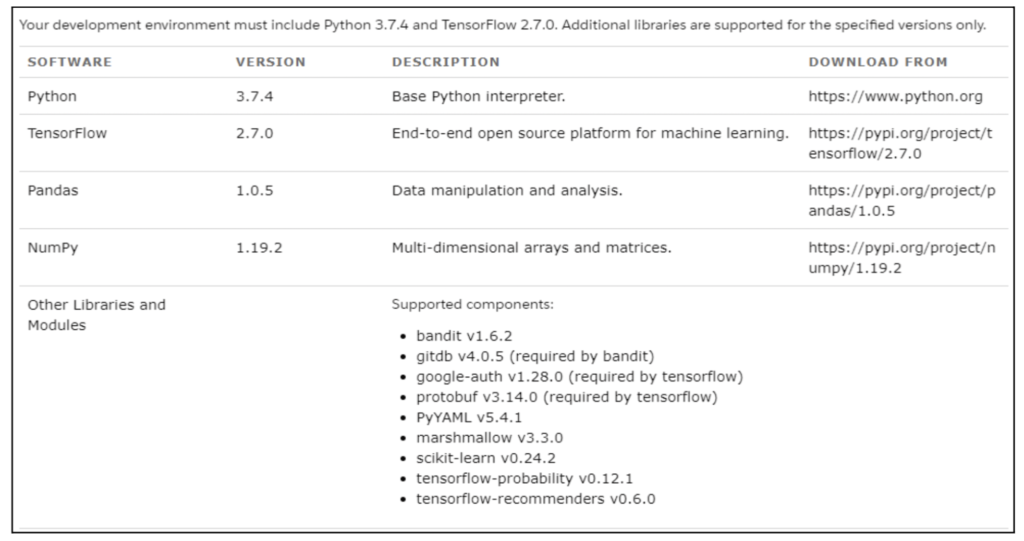
Add the supported libraries in the Docker requirements.txt file and create your BYOM image.
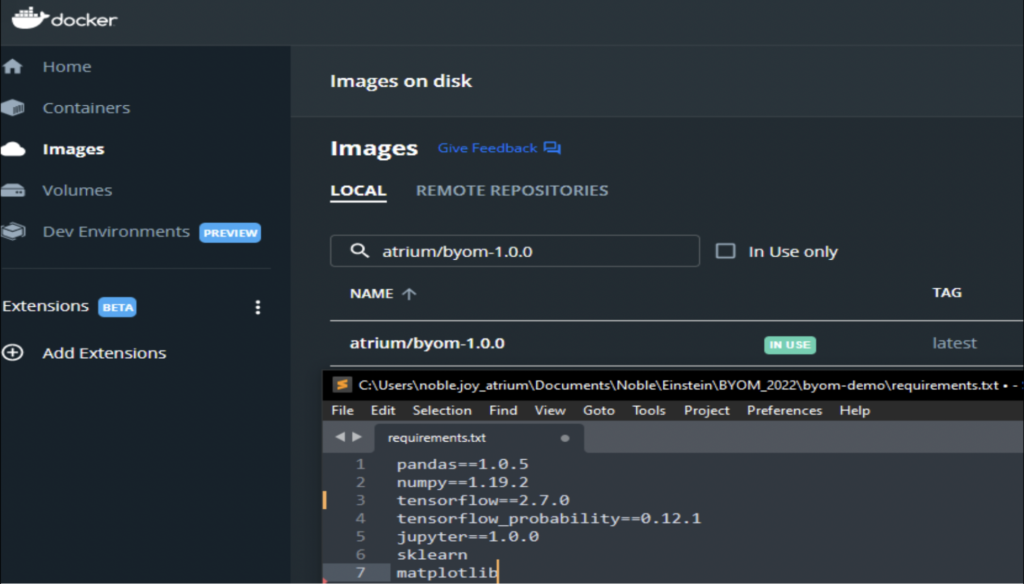
2. Build TensorFlow Model
Let’s build a TensorFlow Multiclass Classification model for solving the Yeast classification problem.
The Yeast dataset has 8 input features and the dependent variable is the Yeast class with 10 values. Screenshots of the dataset and output class values are shown below.

TensorFlow & Keras deep-learning models tend to perform well with multiclass classification problems, especially in cases where the target has many values. Here we have a neural network with 2 hidden layers having 20 neurons each and an output layer with 10 neurons since we have 10 classes. We use the softmax activation function on the output layer, which yields a probability for the corresponding class value. The loss function used is categorical_crossentropy, which penalizes errors in the probabilities predicted by a multiclass classifier. After defining the network, call fit to train and predict to make predictions.


Once you are satisfied with the model results, the next step is to save the model output. Call the save method to save the model assets.

3. Prepare the upload file for the external machine learning model
The final .zip file should include the following files:
- Data_processor.py: This python script defines the preprocessor() and postprocessor() methods. Here you can add custom data transformation logic as needed.
- Saved_model.pb: This is the TensorFlow model object saved in the previous step.
- validation.csv: Pick a sample of rows (no more than 99) and run model predictions. This file is used to validate the model results and make sure it’s working as expected.
- assets folder: Created automatically when the model is saved, do not modify this folder or contents
- variables folder: Created automatically when the model is saved, do not modify this folder or contents
Final folder structure should look like the one shown below.

A sample screenshot of the data_processor file used is below.

The next screenshot is of the validation.csv file. The class given here is the predicted class by the Tensorflow model.

4. Upload the external model to CRMA Model Manager
Log in to Analytics Studio – > Model Manager and click on the ‘Upload Model’ button to upload your model.

Enter Model Name, Description, and Type and click Next

Select the.zip and click Upload

If the validation is successful, then the model will be uploaded and you can view the models in the Uploaded tab.

5. Deploy the external model
Select the model and click Deploy.

Enter Model Name, Prediction Definition and select how you want to deploy the model: new model, add to an existing one, or update an existing model. Select the object connection and segmentation option and then click the Deploy button to deploy the model.

Click on the Deployed tab to view the list of all deployed models.
6. Test the external model
Call the Einstein Prediction Service API to test the model predictions. It returns the predicted class along with the probability scores of each output value.

Einstein APIs can be called by any external applications, so this solution works well for publishing CRM as well as non-CRM models. In addition to the API, deployed external models can also be used for running predictions in other tools, such as:
- Lightning Components
- Bulk scoring
- Async Apex
- Einstein Discovery in Tableau
AI/ML use cases
External models can be used to solve a variety of problems in Einstein Discovery, including
- Regression problems
- Binary classification problems
- Multiclass classification problems
We already saw how a multiclass classification model can be deployed and used in CRMA.
Now let’s take a look at the other two models.
Regression Models – We use regression models to predict a continuous dependent variable. Predicting the total amount of sale, the cost of shipping, the time taken to close a case, etc. are all common regression problems in the CRM world. Here we solve a simple regression problem predicting the price of a house using the Keras sequential model. For this regression problem, we use the RMSprop optimizer and Mean_Squared_Error loss function.

Once the model is saved, uploaded, and deployed, we can call the API to test the predictions. Here the model returns the price of the house (dollar amounts in thousands), which represents a continuous number value.

Binary Classification Models
Most common machine learning problems fall into this category. Lead conversion models, opportunity scoring models, account targeting models, etc. are all commonly used CRM Binary classification models. Here we predict the quality of the wine – good (1) and bad (0). This model uses the sigmoid activation function at the output layer and binary_crossentropy as the loss function.

Let’s make the API call to test the model once deployed. The predicted probability output is 0.98 which shows high confidence that it is a good quality wine. We can also define thresholds to convert the probability score into a predicted output.

This platform will continue to evolve and support many other complex machine-learning problems such as Natural Language Processing (NLP), Clustering, Time Series, and others in addition to the ones supported today.
There is a huge potential for this platform to expand and transform Einstein Discovery to be a powerful tool for seasoned data scientists as well as beginner data analysts to build quick models and solve complex business problems. CRM teams who are currently dependent on enterprise data science teams for solving complex CRM business problems can use this to stand up a new dedicated CRM data science team to solve their CRM problems quickly and more efficiently.
Learn more about our analytics capabilities and how we can help you succeed with different machine learning use cases.

