

Integrating Custom Models with Salesforce Machine Learning
Machine learning problems can be divided broadly into two sections:
- Supervised. With supervised learning, we know what we want to predict. Specifically, we know what the target variable is.
- Unsupervised. With unsupervised learning, we don’t know what we want to predict. Specifically, we are working with raw data and do not have a specific target variable identified or available.
There are many use cases, such as customer segmentation, that require different sets of algorithms in order to reach the recommendations and insights the model can provide. This could be dependent on combining models for clustering and regression or classification, and then integrating with Salesforce to design a robust solution, catering to various use cases in the industry.
Do we always need an autoML tool to implement these solutions? No. Let’s go over a scenario in which customers can implement a machine learning solution and integrate it back into Salesforce to get the predictions and take actions:
We want to use a clustering algorithm to identify the potential high valued customers based on their buying behavior and spend to create a customer segmentation feature and show the predicted customer segment to our salesforce users.
What is Heroku? How does it work with Salesforce?
Heroku is a cloud-based Platform as a Service (PaaS) that provides support on various open source programming languages. Open source is to Heroku as Apex and Lightning are to Salesforce. It allows developers to build, run, and scale applications seamlessly.
To interact with Salesforce, Heroku provides an integration service called Heroku Connect, which provides a bi-directional data synchronization between Salesforce and Heroku PostgresSQL.
3 Components That Will be Leveraged in the Implementation of the Solution
Heroku Connect
It allows for a bi-directional data sync between Salesforce objects and Heroku Postgres. It can be easily configured with the Heroku account and provides a point-and-click interface for the configuration.
Heroku Postgres
This is the cloud Database as a Service for Heroku. It is based on PostgreSQL, an open source database.
Heroku Platform
We can understand the Heroku platform as the place where the code runs. It provides you with virtual containers (aka dynos) that run the apps, which can be written in a variety of programming languages. Scalability can be achieved by just increasing the number of dynos that the app can use for execution.
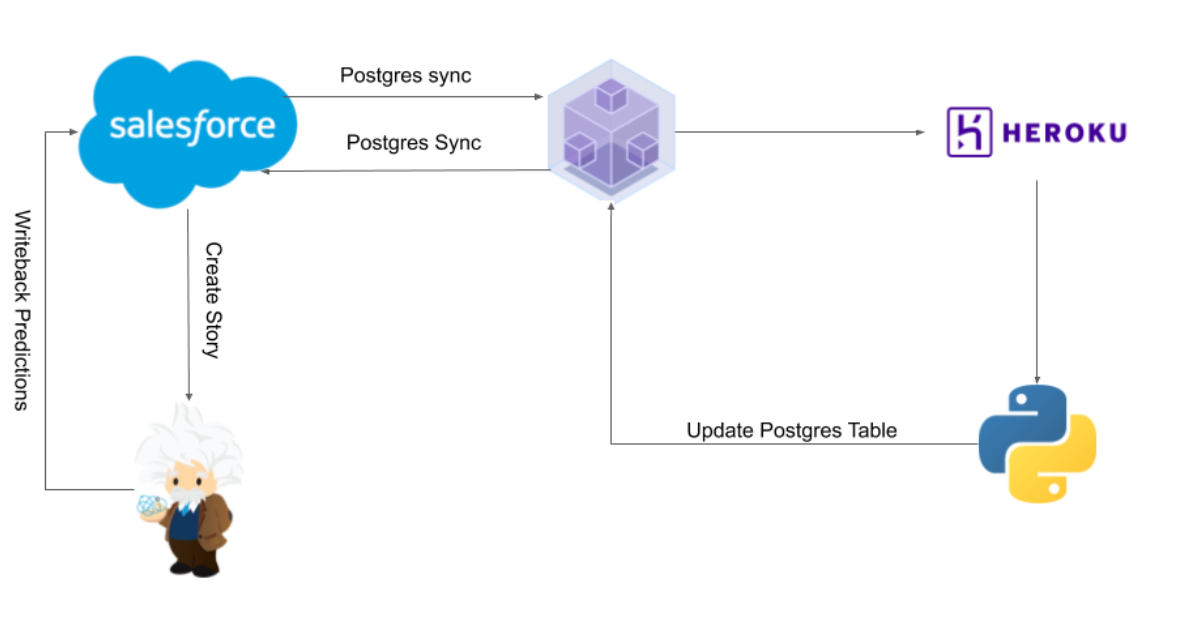
High-Level Architecture
The above architecture leverages Heroku Connect for the bi-directional sync between Salesforce and Heroku Postgres to obtain the data and write back any updates to the Salesforce objects.
Here are a few points regarding the architectural components:
- Postgres holds the Salesforce data in relational tables and creates custom tables to hold the intermediate results. In other words, Postgres works as a data source as well as a staging layer.
- Python is used for data transformation, feature engineering and model training and prediction tasks.
- Heroku provides the platform to host the Python scripts and the execution of the related code.
A Step-by-Step Approach to Solving Our Problem from Earlier
Getting back to the problem we stated earlier:
We want to use a clustering algorithm to identify the potential high valued customers based on their buying behavior and spend to create a customer segmentation feature and show the predicted customer segment to the Salesforce users.
Here is a step-by-step approach to leverage the above architecture to solve the problem:
Step 1: Identify the Data to Support the Solution
In our problem, the data comes from a data store that houses customer data for buying behavior, purchase history, and demographic details. We will leverage this data to train a clustering model that helps us in segmenting the customers.
To view the results in Salesforce, we would need to create the field on the opportunity object that would store the clustering results.
Step 2: Set Up Heroku Connect and Postgres
Assuming there is a Heroku account already set up, configure Heroku Connect for the data sync with the Salesforce org. The configuration is all point and click and the detailed steps for configuration can be accessed here.
Configure a Postgres database to be used with your Heroku app for the data sync. The sync should be set up as bi-directional for the object you want to write the predictions. This would be the opportunity object.
Step 3: Data Manipulation, Cleansing, Feature Engineering, and Modeling
With the initial setup complete for the data sync and writeback, start with the code. We will use Python for the data extraction from Postgres, data manipulation, model training, and predictions.
As we want to perform customer segmentation using clustering, we will use K-means clustering algorithm to identify where a customer belongs. K-means clustering tries to find centroids and assigns the data points which are nearest to the centroids to the same group. Here, centroids are an imaginary or real location that are the center of a cluster or group. The process is iterative and stops when either we find the optimized centroids or when the defined iterations have completed.
Python provides several libraries to complete the required tasks:
- Numpy — scientific computations
- Pandas — read/write datasets
- Sklearn — machine learning library
Numpy and Pandas will take care of any data computations and manipulations required for the task and creating data to train the clustering algorithm.
For training and predictions we will leverage Sklearn. Once the model is trained, we extract it in the form of a pickle file. A pickle file, in simple terms, is a byte stream representation of your object. To use it again, you perform the inverse operation.
Step 4: Deploy the Code to Heroku and Schedule Jobs for Execution of Scripts
After creating all the scripts for extraction, data wrangling, feature engineering, and model training, deploy the code to Heroku. Here, for simplicity’s sake, we will use GitHub as our code repository. Heroku provides direct integration with Git for code deployment.
The Heroku scheduler will run the prediction scripts at the defined intervals to extract the data from Postgres, perform predictions, and update the Postgres tables. The predictions will be written back to Salesforce objects using the Heroku Connect sync we set up in the first step.
Does the Use Case End Here?
No. The predictions can be leveraged in two ways:
- Show it on the Salesforce records and let the user take an action.
- Use the output in Einstein Discovery to predict another result.
Here, let us expand the use case from just predicting the cluster or customer segment to using that segment as a feature in a customer retention model. This customer retention model predicts which customers are going to churn and uses the customer segment as a feature.
This way, the solution expands to just using a custom machine learning model to using the custom machine learning model with Salesforce Einstein to create a robust solution that can cater to a multitude of business problems. Moreover, Salesforce Einstein works with the custom model and provides recommendations as to how the results can be improved further, and insights on the reasons behind the prediction output.
Is This Better Than Using an AutoML Tool?
There is no definitive answer to this question. The solutions can be implemented by leveraging programming languages, such as Python, that give you freedom to implement the solution customized totally to the customer’s requirements.
However, this does come at a cost of maintaining the code base, hyperparameter tuning, model selection, complete testing cycles, bug fixes, deployments, etc. AutoML tools help you by reducing the headache of everything so that you can focus on problem solving. So both of the methods have their pros and cons and customers can choose to use what fits best to their situation.
Where Else Can It Help?
Machine learning projects are not just about getting predictions and creating stories. The data is not always clean as much as we want it to be. This approach allows implementation of:
- Customized data cleansing techniques
- Missing value analysis and imputation
- Feature selection methods like forward and backward selection
- Ability to select from a variety of machine learning algorithms
This can also allow the customers to test if their business requires a complete makeover using AI by implementing a small solution first, before investing in a full-fledged solution or any tool to do the work.
What Do You Recommend to Orchestrate and Coordinate All These Activities?
While this architecture can provide significant value to your CRM users, getting it set up and orchestrated to run seamlessly can be a challenge. Additionally, you may have multiple scenarios where you need AI recommendations, and building out point-to-point solutions for each can become burdensome and difficult to maintain.
We recommend a centralized orchestration layer, such as our Machine Learning Model Broker service, to streamline the user experience and provide users with the insights to improve AI adoption — focused on augmenting the CRM experience with best-of-breed machine learning solutions.
Get Help Implementing a Custom Machine Learning Model and Integrating It With Salesforce
Here we ran through a simple framework on how we can implement a custom machine learning model and integrate it with Salesforce using Heroku. This framework can be used with other PaaS solutions which provide the capability of hosting your code and can be integrated with Salesforce.
Learn more about the services Atrium provides and how we can help you see success with different machine learning use cases.

