


Data Quality: The Atrium Difference
Today, we kick off an ongoing series of Expert Insights featuring Atrium data scientists’ perspectives on data quality. This and future blogs will dive into common patterns of data inadequacy and how Atrium addresses these to more fully realize your data-driven intelligent experience.
Businesses today have more data than ever. With integrated, cloud-based systems, data collection is effortless and automatic. The data-driven intelligent experience is limited not by volume of data, but by quality. Frequently, organizations develop predictive models only to find that their data have too many inconsistencies to be useful inputs to those models. But this by no means implies that you need perfect data before becoming a data-centric organization. At Atrium, we are leading with a holistic approach that improves data quality while delivering useful business insights.
The first step in becoming data-driven is understanding the role of data in the organization. There is never a one-way pipeline from data to making decisions. Rather, today’s insights provide fresh ideas about how to gather and use data tomorrow. What we call the intelligent experience includes taking a complete look at the data surrounding a decision. Sometimes the data quality is too low, so the best action is to add robustness to the data acquisition process and revisit the decision later. This is a common iterative pattern, which we call the Data Life Cycle (Fig. 1). Businesses can embrace this way of thinking regardless of the quality of their data, even long before glamorous AI/ML predictions become feasible.
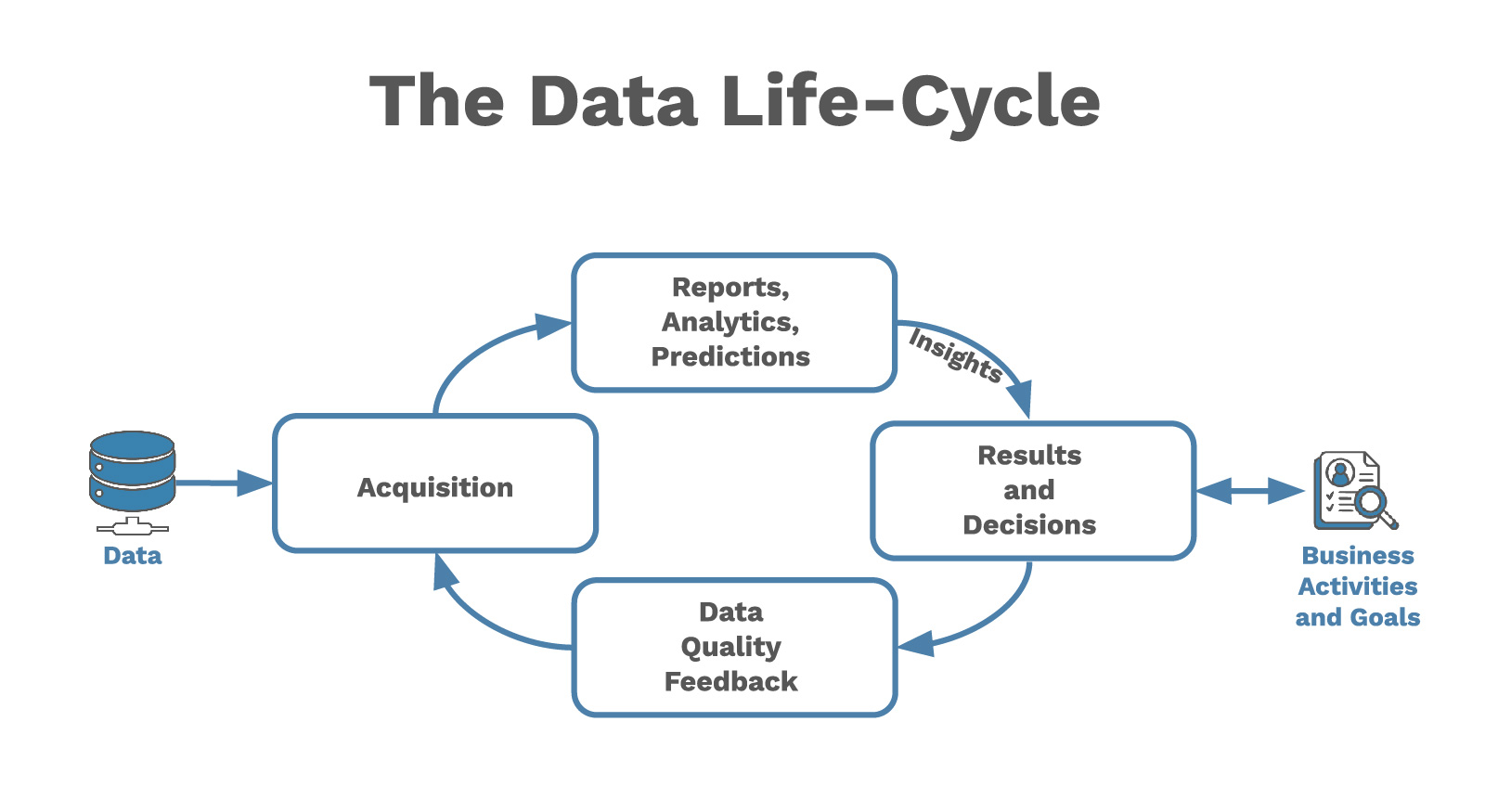
data acquisition process, improving data quality for better insights in the future.
So you have committed to becoming data-driven and reflecting upon your data quality. But what does data quality look like? Low-quality data can take many forms, such as stale date, old data entered using obsolete procedures, blank values, or unreliable values entered carelessly. The consequences of using bad data to make decisions depend on the use case and can range from negligible to making completely incorrect business decisions. Similarly, the solutions can be as simple as updating a data entry page, as complicated as using machine learning methods to repair the data, or may even require modifying business processes to facilitate more robust data collection. Diagnosing and solving data quality issues is not a one-size-fits-all problem, underscoring the need for careful thought and expertise in solving data problems.
Big Problem, Simple Solution
As an example, imagine a user is entering data about new leads. All of the company’s business is in the US, so the data entry form includes a location picklist containing all the 2-letter state abbreviations. These are sorted alphabetically, placing Alaska (AK) as the first, and therefore default, option. When the user is in a hurry, or does not know where the lead is located, they submit the form with the location as “AK” and assume someone will correct it later. Alaska is a small yet important part of the business, with some large accounts but few leads. Non-Alaska leads marked by default as Alaska end up overwhelming the true Alaska leads, the result being that the sales managers have a poor understanding of the Alaska sales pipeline. Their forecasts overestimate the value of future Alaska business and reports tell them to unnecessarily allocate more resources to prepare for new Alaskan accounts.
In our example, the initial solution is easy to implement: add a blank option to the location picklist and make that the first option. This prevents future non-Alaska leads from masking the Alaska data. The next step is to talk with users to understand why they are not inputting accurate locations, then make any changes needed to ensure users can obtain the information and adjust the data entry procedure to reflect the users’ on-the-ground reality. Finally (and most expensively), the company may need to go back and correct errors in older data, which could involve a combination of manual checking and predictive modeling.
These three steps have increasing cost and potentially decreasing ROI. First, adding a blank option to the data entry form is quick, inexpensive, and immediately makes future data more usable. The second step, bringing the users and other internal stakeholders onto the same page, will require at least a few hours of each person’s time and likely a few weeks from those involved in implementing any changes. This step will further improve future data, and additionally, provide insights about the organization’s internal processes and the value of additional data quality improvement. The final step, correcting past data entry, takes weeks or months and will provide value only if the past data are required for reporting, forecasting, etc. For a fast-moving business, the data correction step could be an entirely wasted effort if the first two steps are effective and only the most recent several months’ data are important for downstream uses. A data-centric strategy is key to building good data habits and understanding where more complicated efforts are needed.
Common Data Issues
We see several themes throughout all industries and business units. These can almost always be avoided by analyzing and adjusting the data collection process.
- Default values or the first value in a picklist. Default values or picklists without a blank/none/unknown option make the field implicitly required (as seen in our Alaska example). Make sure that users actually have access to the information and that defaults are truly natural default or initial values for the process or object being captured.
- Low-quality data in required fields. When users cannot leave the data entry form until they enter information they do not actually have, they often enter nonsense or placeholders.
- Inconsistent usage. If fields (and their downstream usage) are not clearly defined, users may round differently, use different units, or use different labels. Changes in uses or definitions need to be documented and understood by consumers of the data.
- Null values. Perhaps the most familiar data quality issue, little can be learned when data are blank, null, or missing. The impact of missing data depends on how many are missing and why they are missing.
- Outliers. Unusual values can occur for many different reasons, some naturally and others because of data quality problems. Outliers themselves are not necessarily indicative of poor data quality, but they are often the first sign of other data quality issues. Outliers may be unintentional mistakes or made-up data intentionally entered by a user who did not have access to the true information.
All of these are sources of systematic bias and will be covered in-depth in future articles.
Diagnosis and Solutions
Too often, data quality does not become a concern until companies decide to implement large-scale predictive models, realizing only during model training that the features expected to be informative are mostly null or plagued by inconsistencies. These issues are remedied most efficiently by proactively applying business knowledge—in designing the data acquisition process, combine input from both the users generating the data and the stakeholders who will use the data. Doing this before implementing predictive models will save considerable time and cost by reducing the effort that goes into developing the models. That does not mean that businesses need to become experts on data collection, only that they keep in mind that all activities generate data that will potentially be useful later on.
Again, there is no universal fit, but we can share the questions to ask to point toward a solution. Do we see any of the data quality patterns listed above? Are there obvious patterns in which records are low quality? Some exploratory analytics can be very helpful in answering these. Next, what are the present and future downstream uses of the data? Are any decisions or activities hindered by low-quality data? This is especially important where AI/ML methods are employed because those methods applied to low-quality input data can lead to misleading results. Answering these questions will help you understand the value of data quality improvement in terms of improved efficiency or insights.
Once you have assessed the role and value of data in your organization, you can evaluate the effort required to remediate the problems. Are there errors that are easily corrected by a small team? Will it require a company-wide effort? Some data quality problems may be addressed simply while others will require an automated algorithmic approach. Atrium can help you understand which option is the most appropriate, and for the tougher situations, our data science team is pursuing ongoing R&D around automated data cleansing and bias correction.
Trustworthy data are required for optimal AI/ML insights and are an integral part of the intelligent experience. Data quality is improved through data-centric strategy, not necessarily complex algorithms. With our multi-talented team of strategists, integration experts, and data scientists, Atrium is blazing a trail of data quality innovation.

