

How to Keep Data Debt From Reducing the Value of a Data-Driven Organization
In 2017, the Economist published a report titled “The world’s most valuable resource is no longer oil, but data.” This led many experts within industry to call for companies to become “data-driven organizations”.
A data-driven organization is a company that not only focuses on collecting raw data, but also understands that to be truly data-driven, they need to dig deeper into the data gatherer, refine it, and find ways to use the information gleaned from the data to drive growth and profitability. This means working with the right kind of data whenever it is needed. It could happen in many ways, including observing customer behavior, gathering survey responses, analyzing demographic data, and more.
Analysts have taken note, and organizations such as McKinsey have noted that data-driven organizations are nearly 3x more likely to have a higher ROI, and 23 times more likely to outperform non-data-driven firms in acquiring new customers.
With that said, collecting data and mining it for meaningful information has proven to be extremely challenging for most companies and poor quality data remains an issue. The Harvard Business Review noted in 2017 that only 3% of companies’ data meets even basic quality standards, for example.
How did this situation develop, and what can a data-driven organization do to improve data quality and truly benefit from their most valuable asset?
What is data debt?
Many companies have embarked on agile software development programs over the past decade as a part of their digital transformation. The term technical debt is now widely understood: as code is developed, sometimes features are deferred, or easy/quick solutions are chosen instead of more thoughtful ones which would take longer (or be more difficult) to develop. There is ultimately a cost to this, whether in the cost of having to go back and refactor or reengineer (or entirely rewrite) this code later, or in inefficiency introduced due to the lack of features or less elegant solution.
Similarly, data debt can be defined as the cost in delaying spending the time to clean or organize data in a meaningful way to maximize the benefit an organization can realize from it. For example, if you have data stores which are poorly documented, then each time someone wants to use the data, they need to spend extra labor and time (and therefore money) analyzing the data and ensuring they understand what the data is, and determining if it can meet their needs. As this cost is incurred each time the data is used, there is a tangible and substantial debt associated with the poor documentation associated with the data.
What are the types of data debt that companies accrue?
Software development thought leader Martin Fowler has an excellent framework for measuring technical debt—the technical debt quadrant concept, which we can adapt for discussing data debt in a similar manner.
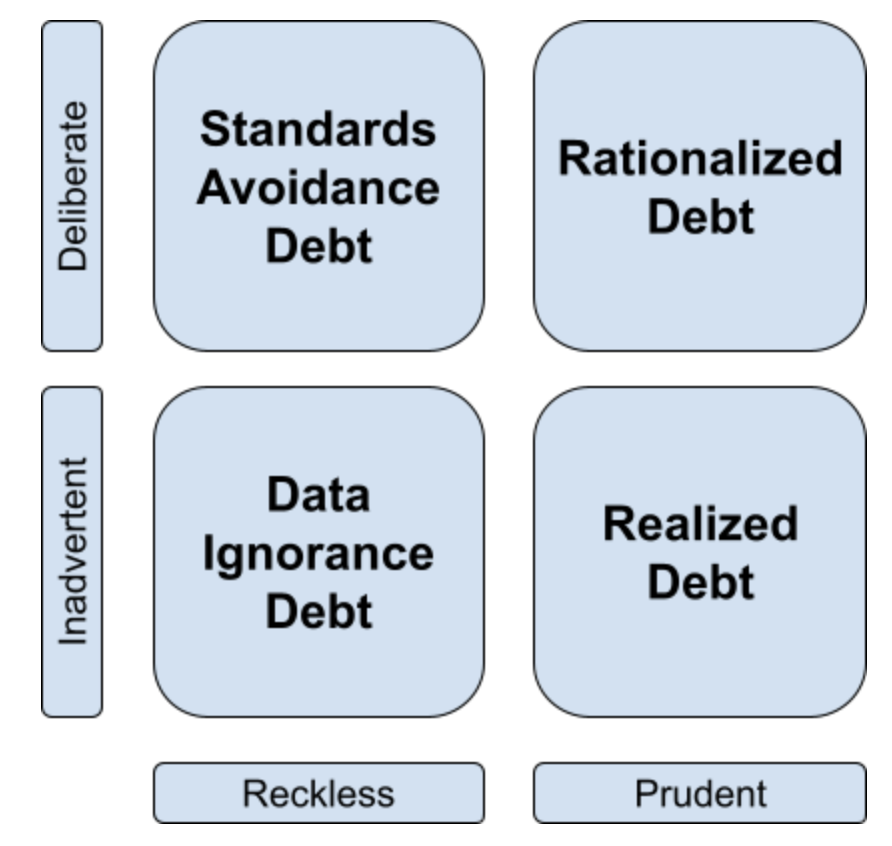
Data Ignorance Debt
This type of debt is incurred when organizations move quickly and create something that will be expensive to re-do later (for example, creating redundant data across data stores which will need to be kept in sync or otherwise rationalized later). We do not acknowledge the impact of the data debt we are creating, which often results in making short-term decisions without any consideration for long-term implications.
Standards Avoidance Debt
This type of debt is similar to Data Ignorance debt. But in this case, we know that what we’re doing is not the best way. However, pressure to move quickly, politics, or a disregard for future impacts causes us to move forward with poor design decisions (or making no allowances for future debt remediation) despite knowing the cost of these decisions. This is the most common form of data debt, where short term objectives are prioritized over enterprise spending on data management.
Realized Debt
When an organization moves into the debt realization quadrant, it typically means they have learned lessons, often the “hard way” from previous projects, and are fully aware of the cost of those mistakes. Typically in this phase, the importance of data governance and building processes to avoid or remediate data debt becomes clear.
Rationalized Debt
This type of debt is when an organization chooses to accrue data debt despite the realization of the costs being incurred. Effectively, the organization is choosing to accrue future cost and risk in order to make progress. Unlike Standards Avoidance Debt, however, the organization has done careful analysis and determined that the cost of the debt is the right choice at the moment, and a plan is put in place to lower the debt at a later time. This can be a prudent business decision at the moment, but only with a full understanding of the debt being incurred.
What are the costs or implications of having data debt as a data-driven organization?
While data debt can take many forms, the costs associated with it can be even more complex to quantify. There is obviously the resource costs associated with future remediation of data debt, but there is also the cost of inefficiencies introduced as a result of having the data debt in place. For example:
- Analytics projects may be slowed down significantly as analysts need to spend significant unplanned time reviewing, inventorying, and documenting data
- Marketing campaigns may underperform due to poor segmentation, and marketing resources may spend significantly more time curating or cleaning lists as a result of poor or confusing data
- Product teams may build features that fail, due to lack of insight into the target audience or market
- Customer success teams damage customer loyalty or increase churn by reaching out to duplicate records, creating billing errors, or providing poor handoffs between teams due to data issues
What can we do about data debt?
In looking at our data debt quadrant, there are steps companies can take to address data debt, but the right actions often depend on which quadrant the debt resides within. Like all debts, however, they must be paid eventually—either slowly over time (and with interest) or in a big chunk that pays off the debt. Organizations which do not address their data debt will find that the outstanding balance continues to grow.
A key first step for an organization is to set up a data management program, which can focus on how to pay for it and set a policy for how much data debt is tolerable and how to educate the organization about this powerful tool.
Once a data management program is defined, funded, and staffed, the organization needs to focus on data debt in all quadrants. Training programs, remediation projects, or even wholesale rebuilding of poorly implemented data or BI solutions need to be put in place in order to reduce debt over time, and unlock the maximum value from the data the company has acquired.
Next Steps
Similar to technical debt, organizations must focus on reviewing data debt and then be strategic and intentional about addressing it. Failure to do so can have tremendous impacts on decision-making throughout the company, and can minimize the value of investments in collecting or analyzing the data in the first place.
Executive sponsorship is critical to the success of data management programs. Many organizations are creating a Chief Data Officer (CDO) role which is responsible for championing these efforts and leading the teams that are responsible for data throughout the enterprise.
Project teams should also be conscious of the influences that their decisions can have on data and dedicate time during or after projects to address these impacts.
Inaction isn’t an option. With the increasing velocity and volume of data, organizations must find a way to effectively manage this data or face the impacts of data debt. If you need help with data engineering, data infrastructure, or data strategy in general, we can help.
