

Surfacing Einstein Discovery Results in Your Snowflake Data
A single source of data will allow organizations to quickly build data models and analytical dashboards using data across business units and systems. A native connector from Einstein to Snowflake eliminates the need for potentially costly middleware and significantly simplifies the integration between these systems.
But before we can dig into building a model with Einstein Discovery using the Snowflake connector, let’s review the two systems independently.
What is Snowflake?
Snowflake is a modern cloud version of the data warehouse. Lifted straight from their website, they describe their product as:
Snowflake’s cloud data platform supports a multi-cloud strategy, including a cross-cloud approach to mix and match clouds as you see fit. Snowflake is available globally on AWS, Azure and Google Cloud Platform. With a common and interchangeable code base, Snowflake delivers advantages such as global data replication, which means you can move your data to any cloud in any region, without having to re-code your applications or learn new skills.
In practical terms, this means that if you’ve ever used a DBMS system before (e.g., Oracle, Terradata, Netezza), you’ll have a great sense of familiarity. However, Snowflake is much more scalable, as it utilizes a multi-tenant cloud.
What is Einstein Discovery?
Einstein Discovery is Salesforce’s machine learning and AI platform. It features an easy-to-navigate UI that allows citizen data scientists to create predictive models without the need to learn languages like R or Python.
How to Build a Predictive Model with Einstein Discovery and See the Results in Your Snowflake Data
Using Salesforce’s Einstein Prediction Service Scoring API, you can create predictive models in Einstein Discovery and surface the results in your Snowflake data. But before you can use the Einstein Prediction Service Scoring API, you’ll need to first build a model in Einstein Discovery. This is usually done with a dataset that you’ve created in Einstein Analytics. Thankfully, Einstein Analytics has a built-in connector for Snowflake that makes creating a training dataset from your Snowflake data easy.
Using the Snowflake Connector in Einstein Analytics
- Go to your Data Manager, select the “Connect” menu, then “Connect to Data.” In the pop-up, press the “+” icon to create a new connection, and then scroll down to find Snowflake.

- Enter your Snowflake account details in the pop-up, and select “Test and Save.”
- After the connection is successfully established, select the new connection you made to see a list of available tables. Select the table you wish to pull data from, and then select the fields you wish to use in your model training.
- Note: Einstein fields have different limits than Snowflake. If your Snowflake field exceeds Einstein’s limits, the field will not be available to select. For example, if your Snowflake field is a varchar of 50,000 characters, it exceeds the Einstein limit of 32,000. In this case, you will not see an error, but you will also not be able to select the field in the list.
- After you’ve selected the fields you want to use, press “Continue,” and you’ll be presented with a data preview. You can use this preview to create filters and check that you are getting the correct data.
Building the Recipe for the Training Data
Once you’ve selected your fields, you can now create a dataset using a recipe. You’ll do this in the Connect menu of the Data Manager.
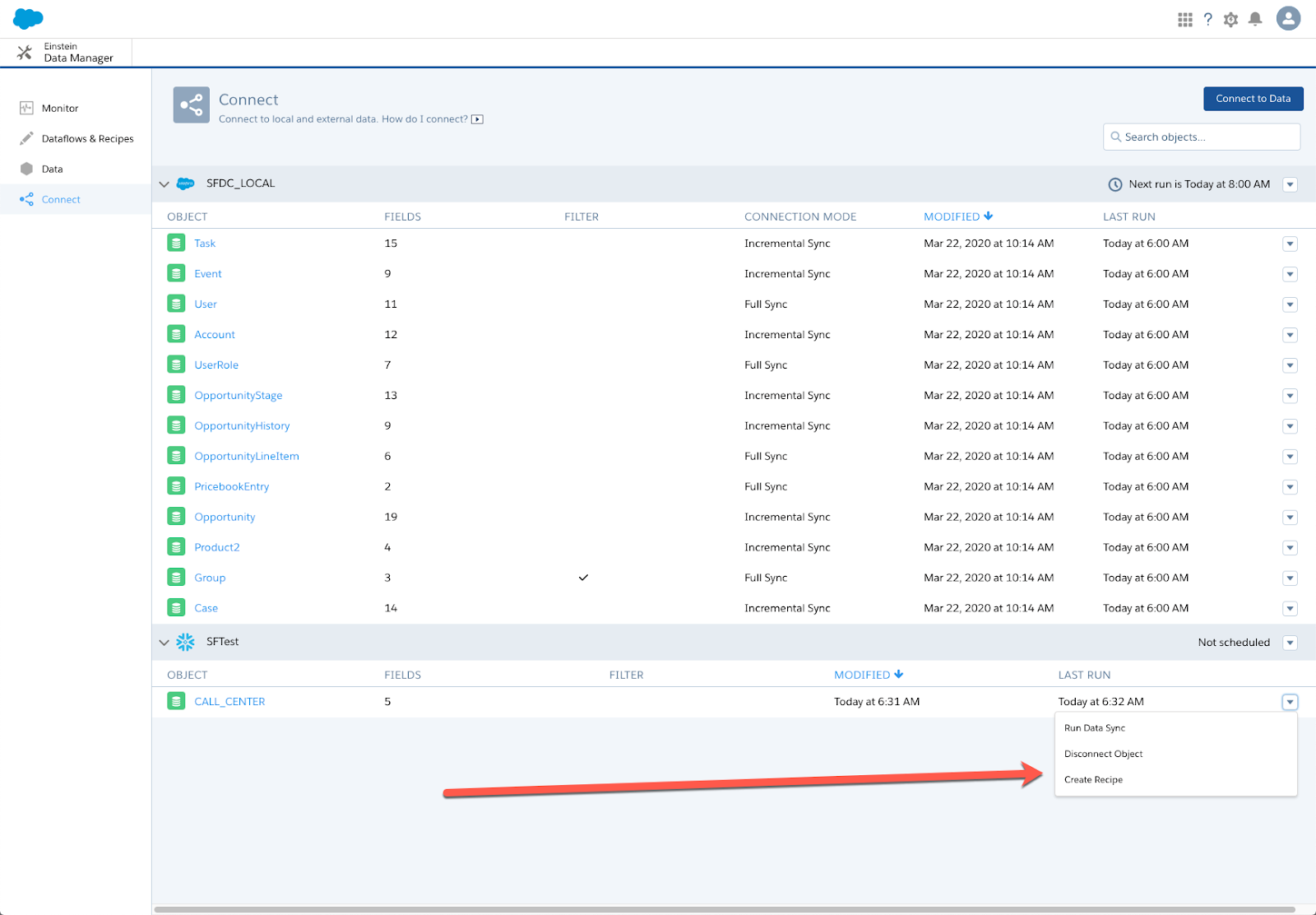
Using the recipe, you can further define and transform your training data for the model. After you’ve completed the recipe, you’ll run it to create your dataset.
At this point, you’ll want to follow these guidelines to create your first model. The steps are the same whether you’re using an external data source or Salesforce data. Be sure to note which features (i.e., fields) you use in your model, as you’ll need those in the next steps.
Using the Einstein Prediction Service Scoring API
Once you’ve created your data model using your training data, you are ready to score your Snowflake data using the Einstein Prediction Service Scoring API. This can be done in your programming language of choice as long as it has a method for communicating with REST API services.
To use the service, you’ll need to use several endpoints in order to get your predictions.
Prediction Definition Service
You’ll use this service to find your prediction definition’s ID. You’ll use this ID in future calls to the services. Calling the end point will return a list of all possible predictions set up in your Einstein installation. You can use the label field to filter to the one you wish to use.
Calling the service is as easy as using the endpoint (/services/data/v48.0/smartdatadiscovery/predictiondefinitions GET) as parsing through the return, which will look something like below.
Prediction Service
This is the service in which you will call repeatedly to get your predictions. Using the ID from the Prediction Definition Service, you will make a call to the endpoint (/services/data/v48.0/smartdatadiscovery/predict POST) with your data in a format similar to the one below. Note: you can send more than one row at a time in your call.
Below I’ve highlighted the prediction ID that you would use from the earlier call. In addition to the ID, you’ll need to provide the columns you are sending (which should match your model features), and the data in the “rows” section.
Getting Your Results into Snowflake
A best practice would be to query your data in batches, send that batch to the prediction service, and then store the results in an Amazon S3 bucket (or Azure or Google Cloud equivalent). You could then use Snowflake’s Snowpipes to load the newly predicted data into your table in batches. Using this method could save you time and money in compute resources over smaller, more frequent batches.
Einstein Discovery and Snowflake Support from Atrium
In today’s environment of rapid migration to cloud-based analytics and AI, we’ve partnered with Snowflake to help companies transform their data from operational reporting and analytics to predictive analytics. Do you need support building a predictive model with Einstein Discovery and surfacing the results in your Snowflake data?
Contact us to see how we can help power your data initiatives. You can also sign up for a 30-day free trial of Snowflake!

