

Unleash the Power of AI with Text Classification and Natural Language Processing
Can the words and phrases in a news story reveal the political leanings of its author? Can they testify to the origin of a job posting? What string of exasperated phrases in a customer support chat can indicate the root problem? Answering these questions can be extremely difficult to hand-code, even for an expert in the field. The sheer volume of data necessary to recognize trends leaves behind the realm of human cognition and calls for the data digestion only possible with machine learning. In modern text analysis, natural language processing and AI join forces to build powerful classification algorithms. Below, we’ll investigate the how the models are trained, dive into metrics that are available for evaluating models, and dream up some more use-cases for this family of algorithms.
Data
Text data is big, and you need a lot of it to develop reliable classification algorithms. In the world of natural language processing, a document is any bit of text that we would like to classify. This could be a single sentence, a query in a chat bot, a news article, a Twitter post, a chapter of a book, a State of the Union speech, etc. But in order to train a model to classify documents, we generally need to see many many many already-classified documents. This giant folder of documents is referred to as a corpus. For example, Twitter offers API endpoints to retrieve a firehose of daily tweets; the NLTK distribution comes with full text of many historical States of the Union, text of over 25,000 books, tens-of-thousands of IM messages; BYU has developed the definitive corpus of Wikipedia articles. On the other hand, if your use-case is more specific, bringing forth a corpus from within your own organization may be more appropriate than using an established corpus. That being said, one warning is vitally important: make sure that your corpus is large enough that you can reasonably expect all interesting words that will appear in future documents have appeared in your corpus. More on this in the next section.
Natural Language Processing
Step 2: Encoding a document
What happened to step 1? Good question! Step 1 of natural language processing is preprocessing, in an attempt to cut down on the dimensionality of the data and control for some shortcomings of the various encodings. But in order to understand why we might do that, it’s best to first understand how a naïve encoding might work.
Machine learning models like structured data, such as points in space, in lieu of unstructured data, like sentences. As such, it is important to encode an unstructured document as a point, or sequence of numbers. The simplest technique is known as the bag-of-words model. In this model, a list of every unique word from the entire corpus is recorded in some order. To encode a document, then, just record the number of occurrences of each word in that document. The result is a point in some high-dimensional space that is thought of as a representation of the document.
List of documents:
– I enjoy my new shoes
– Good customer support
– My shoes fell apart
List of unique words:
{I, enjoy, my, new, shoes, good, customer, support, fell, apart}
New document:
– My new shoes are good
Bag-of-words encoding:
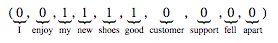
Shortcomings of bag-of-words
The bag-of-words embedding strategy is great for illustration, but it suffers from a few deficiencies. First, if you’ve done your homework and collected enough data, you’d expect the dimension of the embedding space to be very large (equal to the number of unique words). This can make storage and classification costly. Second, you would generally expect common words like “the”, “and”, “a”, etc. to be relatively useless when it comes to classifying a document, but since they are so common, their inclusion can skew measurements like distance between points. Finally, it is reasonable to think that this method throws away too much of the structure of the language. After all, the documents “I do not like it” and “do I not like it?” are encoded in precisely the same way, even though they really indicate a different sentiment. To address this, some models use n-grams (sequences of words) instead of just single words, so the number of occurrences of “I do”, “do not”, “not like”, “like it”, “do I”, “I not” could provide 6 new features (the first document contains an “I do” and the second a “do I”). This blows up the dimensionality again, but at least it retains some semantic structure.
Step 1: Preprocessing
To address some of the shortcomings mentioned in the preceding paragraph, a good deal of preprocessing can be done before the encoding.
- Stop words: Words that are very common to the language of interest, for example I, and, a, the, me, an,… can be removed from a document as a first step. This way, they don’t dominate the word embedding. Furthermore, the dimensionality of the embedding space is decreased by one for each word removed!
- Lemmatizing (or stemming): These are related, but not identical ideas. Lemmatization refers to replacing words with their very simple root forms. For example, are, am, is, was could all be replaced by the bare infinitive be (i.e., forget the tense of every verb). Plural nouns can be made singular, possessives can be dropped, and more. The benefit is that many distinct words in the original document are instead identified as the same word, cutting the dimensionality of the embedding space by orders of magnitude.
- IDF: Inverse document frequency weighting doesn’t help with dimensionality, but it does try to account for some global structure of language. Essentially, if a word appears in many documents, then it shouldn’t be as interesting as one that appears very rarely. So we can weight a word’s count in the bag-of-words encoding inversely to its frequency across the corpus.
AI
The term is ubiquitous, and sometimes its meaning is unclear. In many of the use-cases of natural language processing, we’d like an algorithm to replicate how a human would label a document (we refer to this label as the class of the document). For instance, we may label social media posts about our company as “positive”, “neutral”, or “negative” in tone. Once we’ve labelled a large enough corpus, a machine learning model can be trained to mimic the human labeling. We discuss how in the next paragraph, but rereading the previous sentence should give you some sense of why AI is susceptible to bias: to mimic human labeling is to mimic the biases and flaws in that process.
Training
After the natural language processing steps, we’ve managed to encode every document as a point in some (typically high-dimensional) geometric space, and labelled each point. Many machine learning algorithms simply ask: can I slice space into pieces in such a way that each class falls mostly in one of these pieces? Figure 1 shows a set of points (projected into two-dimensional space), and the result of training a multiclass logistic regression model. The shading in Figure 1b indicates how new points would be labeled.
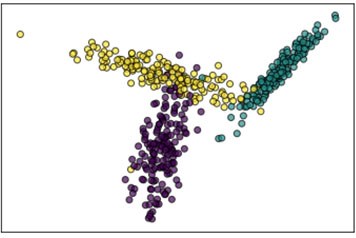

Many machine learning models exist, and they have different levels of effectiveness depending on the shape of the data. But in almost no scenario should you find perfect training accuracy. If you do, it may indicate that you have overfit your data.
Model Metrics
Most models are trained by trying to maximize some accuracy score when the model makes predictions on the input data. It is important to withhold a test set from this process that the model never sees when it is training. After the training is complete, we use this test set to measure the accuracy of the model on new data. This way, we can get an idea of how the model will do when it is exposed to new data when in production. However, accuracy is not the only measure of the usefulness of a model. Below are some model metrics that can be used to understand how the model performs on the test data.
- Accuracy: What fraction of the test data is correctly labelled? This is the most coarse measurement, but very easy to understand. The biggest drawback is that if there are large class imbalances, the accuracy is unlikely to tell you much. In the social media reviews use-case, if 950 reviews are positive, 10 reviews are neutral, and 40 reviews are negative, a very accurate model would label every review as positive and receive an accuracy of 95%. This model doesn’t provide any business lift at all!
- Precision and recall: These measures are more granular, but require us to only consider two classes, call them Yes and No. Precision is simply the accuracy among all examples that the model labels Yes, while recall is the accuracy among all examples that should be labeled Yes. Looking at both is instructive: a model can be made more sensitive, so that it labels more examples as Yes. This could increase recall, since the model misses fewer Yes examples, but it could also decrease precision, since the model may misfire on more No examples. Business requirements should dictate the balance between these measurements.
- F1 score: The (geometric) average of precision and recall. A high F1 score indicates good balance between precision and recall, but it is ignorant to business requirement (for instance, a requirement that False Positives be very rare).
- Confusion Matrix: The confusion matrix is a table with columns corresponding to true labels, and rows corresponding to model labels. The entry in the row i and column j is the number of test examples that were labeled i and whose real label is j. Examples that contribute to the counts on the diagonal were correctly classified. Examples that contribute to counts off of the diagonal were incorrectly classified, where the model was confused. See Figure 2.

Each of these measurements gives us a finer-grained understanding of the accuracy score. More importantly, the business case should what it means to be a “good” model. Let’s explore this in some use-cases.
Use Cases
Text classification is ubiquitous in the modern business context. Below are some common use-cases to inspire your data team.
- Sentiment analysis: How are customers reviewing your business or products on social media? Google reviews, Yelp contributions, Facebook posts, Twitter mentions and more can be used to track customer sentiment, either to head off escalating service complaints, or to showcase positive momentum. Notice that good accuracy would be nice, but it is worth considering a model that is sensitive to negative reviews. Hopefully, they will be more rare than their positive counterparts, which means this sensitivity will have to be carefully calibrated. It may cost very little to incorrectly flag a positive review as negative and send it to a Customer Satisfaction Specialist for further analysis, but may be very costly to incorrectly flag a negative review as positive and miss a brewing escalation.
- Customer Service Case Classification: A customer is patiently waiting for assistance with regards to one of your product lines. But which one, and what is the nature of the problem? If the customer was prompted to type a description of their problem in a chat dialogue, text classification can be applied to determine which CSR specialization would apply best to the given scenario.
- News summaries: Who has time to read an entire article these days? More complex models can be used to glean the key players, events, and timelines in news articles.
- Intelligent communication labeling: Your Gmail inbox benefits greatly from the organization provided by automatic labeling. Commercial promotions, social messages, and important emails are automatically separated using a text classification.
- Spam filtering: This one goes without saying, and is already implemented on many email platforms. Here again, sensitivity can be an issue. If an algorithm misclassifies ham (real messages from real people) as spam, you may miss an important message.
Summary
Text classification is a robust and well-studied problem with both out-of-the-box solutions and customizable models. The workflow is quite simple: collect and label a lot of documents, apply preprocessing, document embedding, and appropriate machine learning algorithm to build a classification model. Using the test data, carefully calibrate thresholds to help ensure misclassifications are palatable. Then, deploy the model into production, spend more time getting coffee, and less time manually labelling your text documents.
Many CRM platforms offer pre-fabricated models which only need labeled documents and hide all of the modelling in the background. These solutions give users the chance to quickly spin up usable (if not exceptional) models, then iterate on them to improve over time. So if natural language processing with machine learning is that easy, maybe it’s time to start asking where automatic text classification can provide lift in your organization. Not sure where to start? Atrium is here to help.

