

Data Lake vs Data Warehouse: What’s the Difference?
Do you ever wonder where your information is stored when you log into any of your online accounts? What about when you take a picture and back it up on the cloud, where does it go and how is it stored? There’s a whole science around data storage, and you may have heard the terms “data warehouse” and “data lake.” But what exactly are these terms and how are they different?
It’s a fairly straightforward concept, and just like most things in the tech world, they are both constantly evolving. As businesses compete to get an edge against each other, they’re often looking into ways they can cut costs and improve efficiency. Data storage is a key area, and there are exciting new developments in the field around combining the benefits of the two traditional paradigms. Learn more about what a data lake vs data warehouse is below:
Data Warehouse
The traditional data warehouse is very structured. Think of it as a Google sheet or an Excel spreadsheet. There are columns, and every data point in that column needs to be the same type, such as text or integers. If you try to enter anything other than a date in a column that expects one, there are rules in place to prevent this. Data warehouses work very well with Salesforce because it’s structured the same way. The star and the snowflake icons in the graphic refer to the two main types of schemas in data warehouses.

When data is loaded to a warehouse, it usually has to go through an ETL process to fit the schema. The transformation process is often heavy, but once it’s in there, it’s easily accessible and simple for analysts to understand.
Data Lake
Data lakes are similar to cloud storage services like Google Drive. You can put whatever you want in there, be it files, photos, or whatever the business needs to be storing. In essence, it doesn’t have to be structured. A lot of data lakes are optimized for operational use cases instead of analytics.
A big difference from warehouses to lakes is the shift from ETL to ELT. With a data lake, you extract from a data source, and then you just load it. You don’t do any transformation whatsoever. The transformation happens later, either within the data lake or through some other process. This eliminates the need to figure out the correct schema ahead of time for every user that needs to access it. End users effectively take the transform step off your hands.
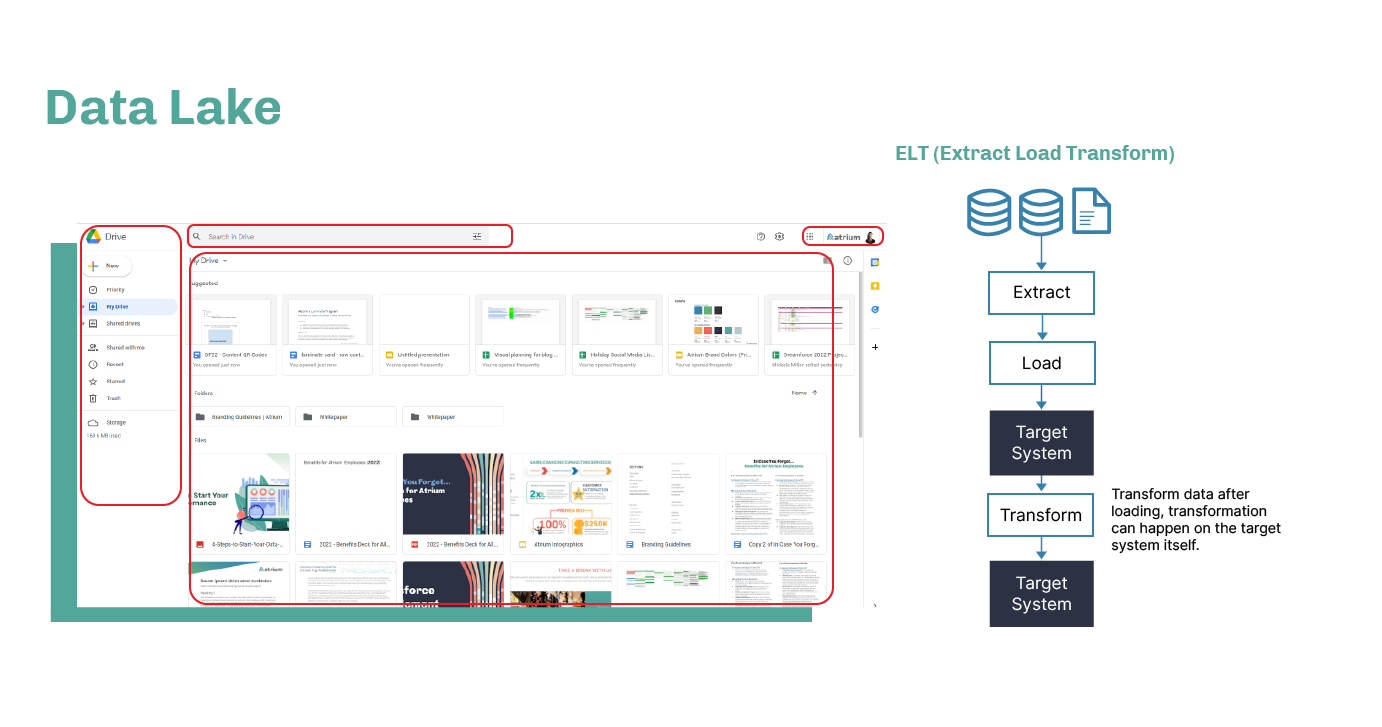
The exclamation and question marks in the graphic symbolize a common data lake quagmire. They often become more of a data swamp where nobody knows what’s in there, where to find it, or how to access it.
Lakehouse
The stigma around data warehouses is that they’re old and slow. Data lakes also have a stigma that they’re messy and nobody knows what to do with them. That may be so, but they both have core capabilities that we want. Some organizations are using both, but shipping data back and forth can duplicate your storage cost and the transformation costs.
The idea of a data lakehouse is to take the best of the data warehouse and the data lake. Having one hub for all your data makes a lot of sense to an organization because a single data repository requires less time and budget to administer than a multiple-solution system.
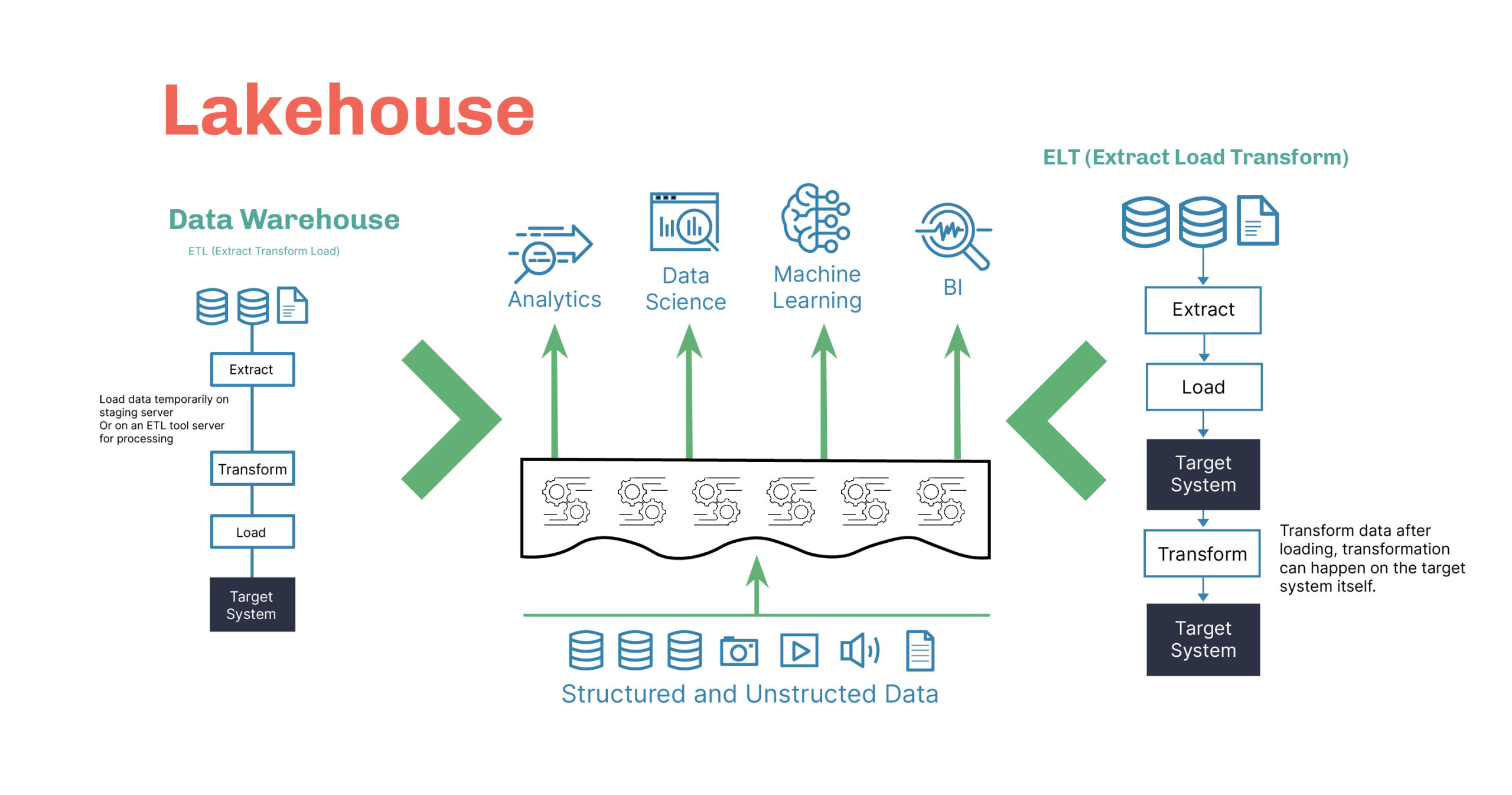
This also gives you direct access to a broader set of BI tools, and it provides a simplified data governance due to its having one control point. While this is a relatively newer concept, we’re already starting to see companies deploy the lakehouse model.
In short, data lakehouses might be what we’d end up with if we redesigned the traditional data warehouse with modern technology. Lakehouses allow us to enforce data structure rules and employ other management features on the non-structured data that we’d expect to find in a data lake.
If you need help with data engineering, data infrastructure, or data strategy in general, we can help.
