

What Are Recommendation Systems and How Are They Transforming Our Markets?
A Recommendation System is an application capable of presenting a user a suggestion, obtained based on users’ preferences and the preferences of a community with likes and opinions similar to the user. These systems are so widespread that many users interact with them without even realizing it.They are one of the most successful and widely-used machine-learning applications in business.
By leveraging the power of data and machine learning, recommendation systems find the match between users and items and impute their similarities to provide users with personalized content.
The Facebook newsfeed, Google Ads, YouTube suggested videos, suggested Amazon products, Netflix and Spotify suggestions are a few instances of recommendation systems at work.
Why are these systems needed?
Recommendation Systems are critical for today’s industries as they enhance the overall user experience. Therefore, they have a hand in increasing site traffic, sales, and leads because users find it simpler to access the stuff they are interested in. The users start to feel known and understood as companies can gain and retain customers by sending out offers and suggestions via email, messages, and notifications that are best suited for their profiles.
This way, companies get a competitive advantage over their competitors and reduce the threat of losing customers.
How does a recommendation system work?
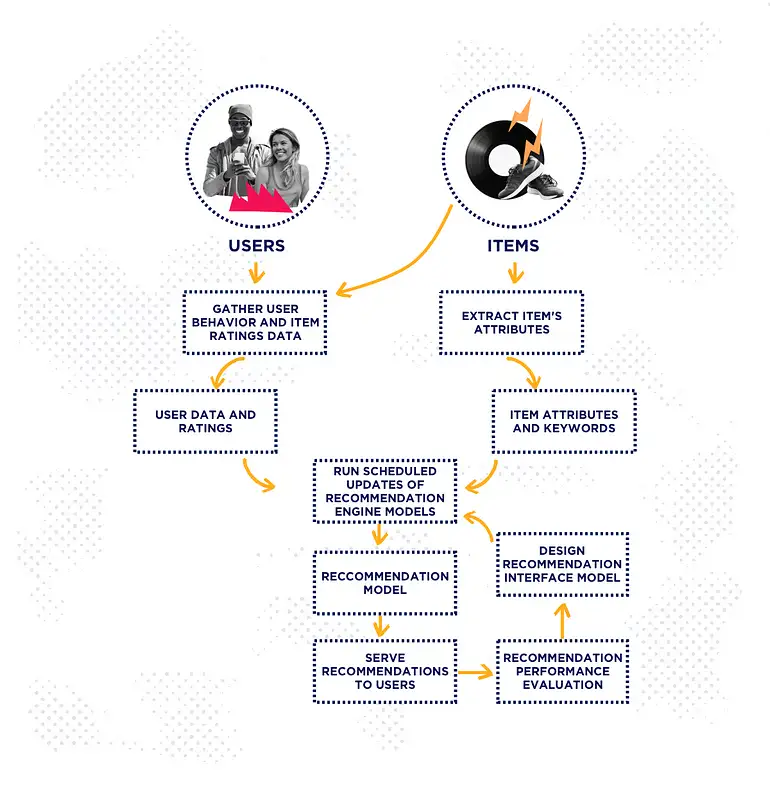
Image source: https://www.iteratorshq.com/blog/an-introduction-recommender-systems-9-easy-examples/
Recommendation systems function with a variety of information:
a. Implicit Rating or User-Item information: This information is generated when the user interacts with an item. Examples include clicks, views, and purchases.
b. Explicit Rating: The user provides these ratings. It is possible to infer a user’s choice. Star ratings, reviews, comments, and likes are a few examples.
c. Characteristic information: This is information about the user and the items. This type of information helps build item-item and user-user similarity.
The measure of similarity is calculated based on the distance between the information. Similarity and distance follow an inverse relationship.
The types of similarity indexes are listed below:
Euclidean Distance is the length of the line segment connecting two coordinates.
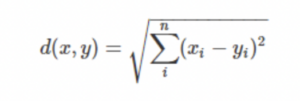
Cosine Similarity is the cosine measure of the angle between two vectors in a multi-dimensional space.
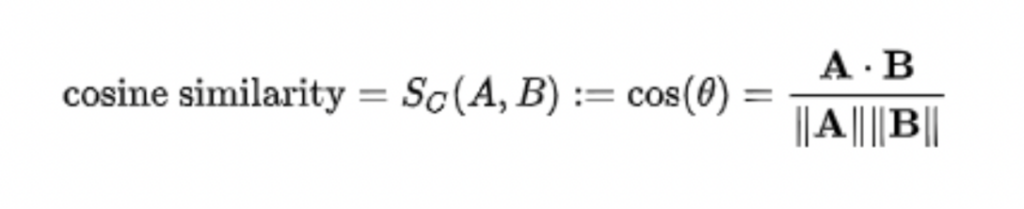
Pearson Coefficient is the measure of linear correlation between two random data points. It’s normalized such that the value lies between the range of [-1,1]
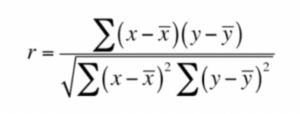
Hamming Distance: In the case of categorical variables.

Manhattan Distance is the absolute difference between two points at right angles.
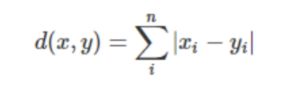
Minkowski Distance is a generalization of both Euclidean(q=2) and Manhattan(q=1) distance.
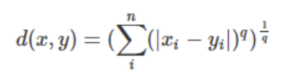
These similarity measures help the recommendation algorithms to build a robust recommendation system.
Types of Recommendation Learning
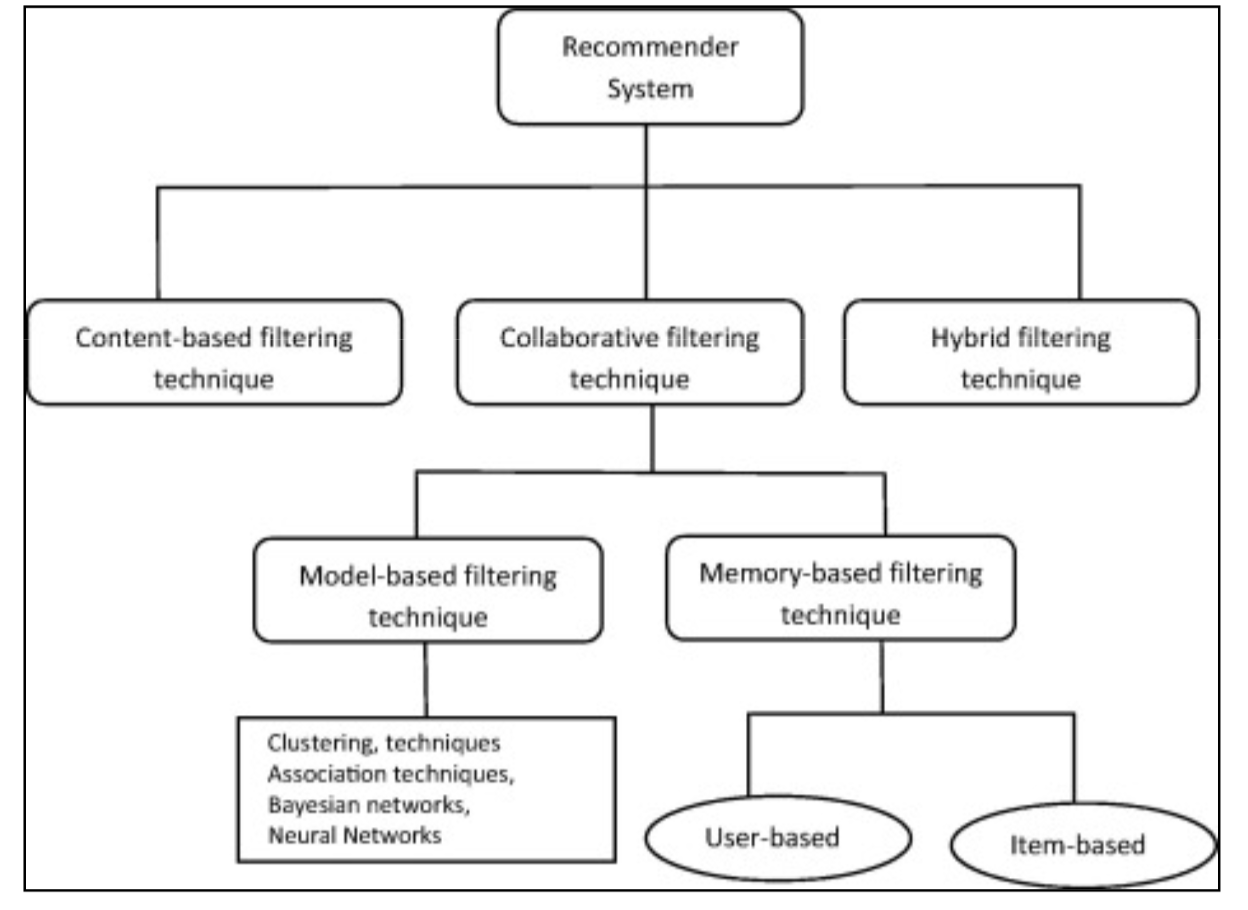
In particular there are four types of recommendation learning algorithms:
a. Popularity-Based Recommendation Learning:
This works on the principle of popularity and trend. This type of learning is not personalized and does not require users’ historical data.
Google News and Youtube Trending Videos work on the principle of popularity based recommendation learning.
b. Content-Based Recommendation Learning:
This type of learning makes use of specific information and operates on the principle of content similarity. Similar items are grouped together based on their characteristics. Based on historical interaction data, user profiles are created and grouped. These details are in text format, which must be converted into numbers in order to easily calculate similarity.
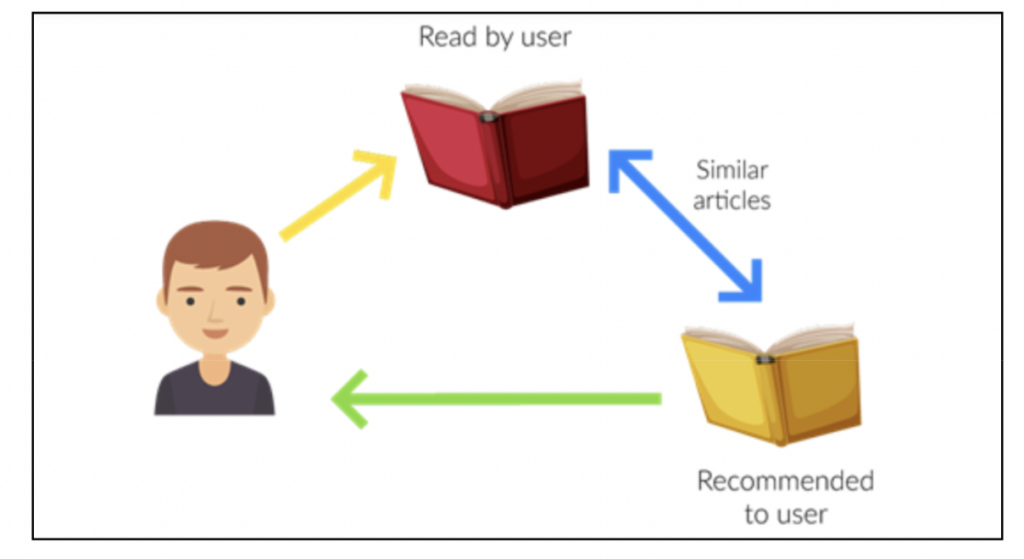
Google and Amazon search recommendations are based on the principle of content-based recommendation learning.
c. Collaborative filtering systems:
This type of learning is based on user-item interactions. It performs better than the Content-Based recommendation system. The interactions are stored in a matrix, where each entry (i,j) represents the interaction between user i and item j. This type of learning requires an ample amount of data in the system.
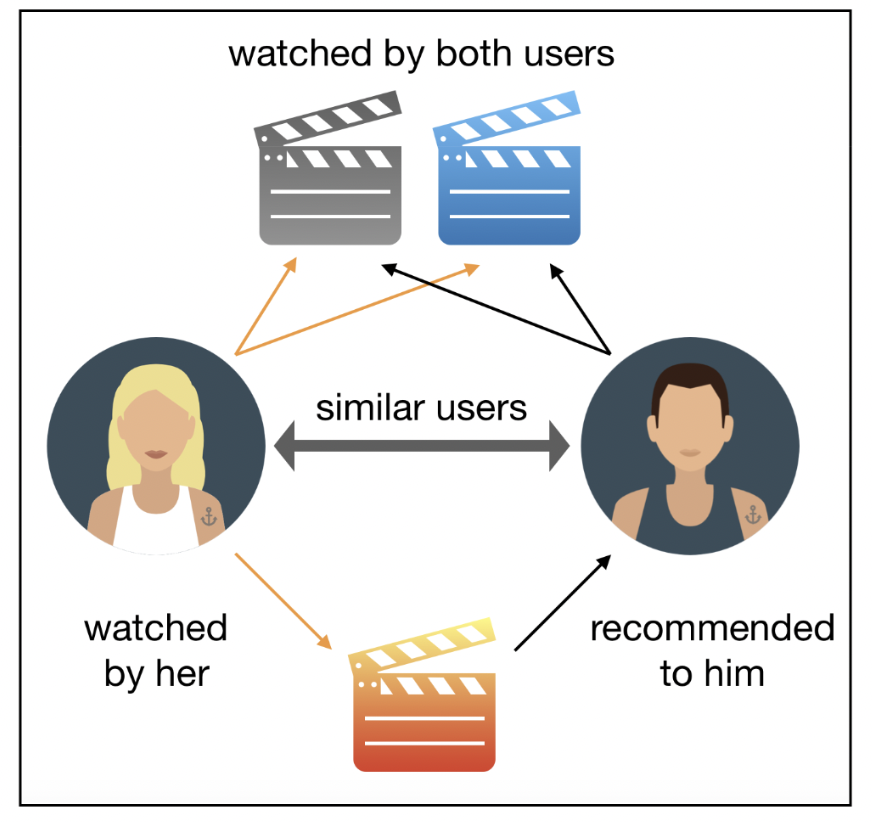
This type of learning can be further divided into User-User Collaborative filtering and User-Item Collaborative filtering.
Spotify’s curated playlists and Netflix’s movie recommendations work on the principle of collaborative filtering systems.
d. Hybrid Systems:
Hybrid recommendation systems use both Content-Based and Collaborative filtering systems to avoid the disadvantages when working with just one kind. First, the content recommendation runs, and then collaborative filtering occurs.
For example, Netflix and Google Ads use the hybrid approach to target new customers.
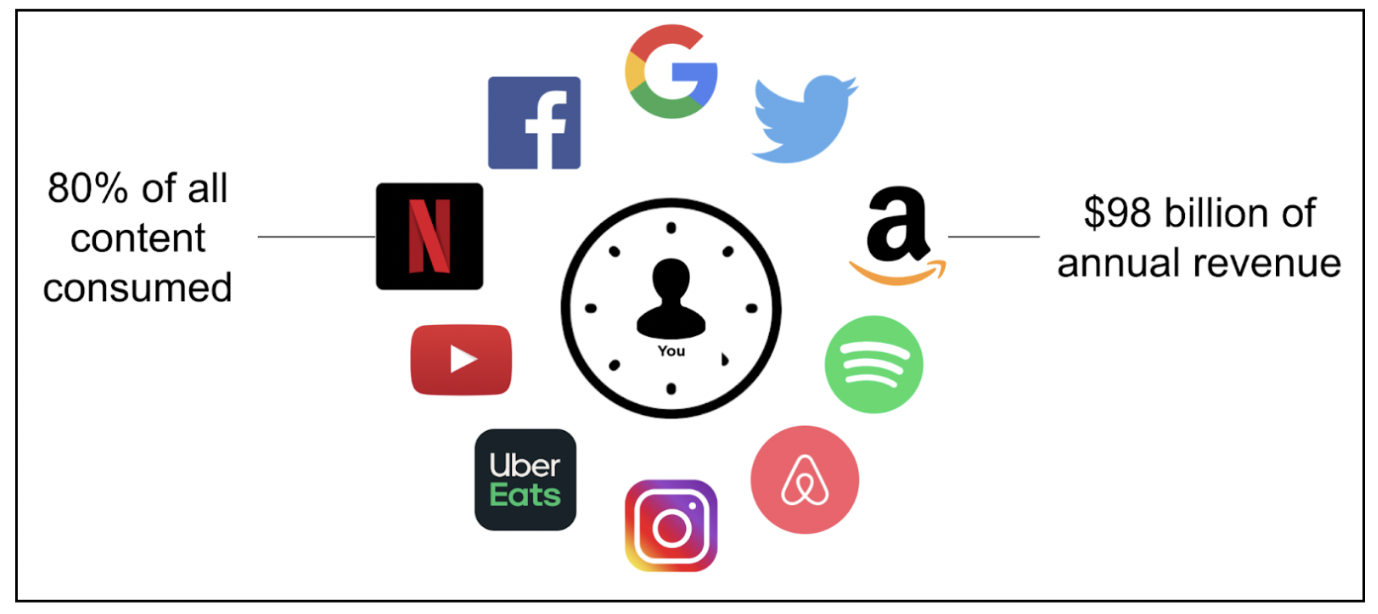
Recommendation systems have changed the entire landscape of the market by changing the way companies function and target customers. The market is more competitive than ever, with data being the most indispensable resource.
Using recommendation systems has become an attractive bet since it’s a win-win situation for both the consumer and the producer. For users, it increases the experience and engagement, and for the business, it generates revenue.
Learn more about Atrium’s data science and machine learning capabilities.
